
Figure 2 - compiler as a black-box for the IDE
The main abstraction behind a text editor is a stream of characters or a sequence of text lines. This abstraction is widely used in the front-end and in the core to work with programs as text files. The API interface of the editor control only works with text and does not “know” about the AST.
In the core, two principal data structures are intertwined together: the text data structure and the AST. The AST is mostly being used by the language service.
Interestingly enough, although the core “knows” about the AST, the interface between the core and the back-end is still based on text in many IDEs. The back-end (e.g. a compiler) acts as a black-box:
Figure 2 - compiler as a black-box for the IDE
The interface of the compiler doesn’t provide “knowledge” about the internal AST data structure: plain text goes in, is internally parsed into a private AST and binaries are generated.
This black-box isn’t extensible. There is no possibility for the user to intercept the process of compilation and to gain access to the internal AST of the compiler. There are a number of scenarios, where a dramatic increase of possibilities in the direction of meta-programming and generative programming would be possible, if only one could have access and work with the compiler’s data structures during the compilation. One could use it for intelligent preprocessing, custom language extensions, code injection, AOP etc. Vendors that provide IDE extensions are often forced to rewrite huge parts of the compiler functionality which otherwise could have been exposed as a clean compiler API operating on the “live” AST structure.
It is also characteristic to all text editors is that the text editor acts like a black-box as well. The current program is being presented to the user, and the user is carrying out actions, which the core is totally unaware of. The meaning of the user’s changes is being completely lost at the very moment when the change is made and only reconstructed with a lot of effort from the background compiler. Basically, the core has to re-parse with every user edit, because it has no knowledge about the intent (the meaning) of the user change. The user could even replace the entire program text in a single action, and only a full re-parse can reconstruct the knowledge about the program.
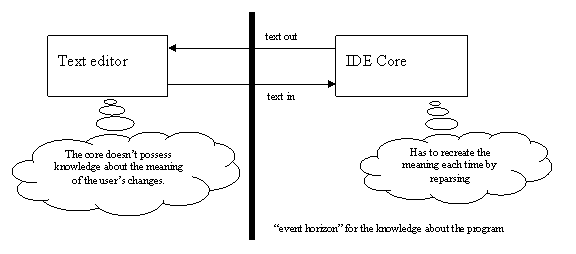
Figure 3 – the editor as a black-box for the IDE
This is the “black hole” of plain text – anything can happen out there and the parser doesn’t have any idea. The IDE doesn’t know what happens to the code between the parsings. This knowledge is lost and found every time. The reparse algorithms can get incredibly complex, when an incremental background compiler is used. In this case, changes are tracked artificially, by recalculating delta differences each time between two known text states or by differentiating “destructive” vs. “harmless” edits (if a reparse is necessary).
It is noteworthy, however, that the decoupling and encapsulation of the text editor and the compiler from the IDE might provide certain flexibility with regard to the implementation – one could change the language (the compiler) without changing the interface that binds the compiler to the outside world. However, as soon as one needs to expose compiler functionality to the rest of the IDE (for example, for the purposes of the language service – intelligent code completion etc.), this observation is not valid anymore – the implementation of the language service has to be kept in sync with all changes to the compiler, regardless if the interface to the compiler changes or not.
The “black-box nature” is at the same time an important advantage of all text editors – it gives the user full flexibility and freedom to make absolutely any changes to the text, in any order, not bound by any semantical constraints. This allows for intermediate editing states where the program is incorrect. In many cases it is easier to bring the program into a temporary incorrect state to reach the desired correct state. A prominent example for incorrect intermediate states is transforming
int i = 0; i = 42;
into
int i = 42;
by placing the caret at the beginning of the second line and pressing [Backspace] several times.At some point the code snippet will look like:
int i = 0i = 42;
which is incorrect, but fully OK as long as this code remains within the editor.
As the editor control is decoupled from the rest of the IDE using a generic language-agnostic API surface, it becomes easy to implement, generic, flexible and almost universally usable.
Text editors allow for editing programs pretty fast, too. Editing speed is an important advantage of text mode, to which programmers are used. It is crucial to preserve this advantage to let users benefit from this.
Another implicit advantage of text editors is familiarity. Text editors are something all developers use all the time during coding, and they got used to it very well. For a programmer, there is basically no need to learn how to use the editor, once a new language or environment comes out. Moreover, text editors are actually very effective, so many developers are actually totally pleased with the editing experience and don’t have any complaints. This, and the fact that text editors are so widespread, will probably be the reason, why structured editors never fully replace text editors.
However the flexibility of text editors comes at a price – the users have to take care of the syntax and formatting. They have to help the editor to convert the program into an intermediate representation by manually separating language constructs with separators like ‘{‘, ‘;’, ‘(‘, ‘//’. Even if the IDE provides automatic code formatting (employing the pretty-printer from the language service) and code snippets to automatically insert constructs like { }, the user is still involved with manually inserting tabs, spaces, blank lines, semicolons etc.
It makes sense to compare usability of text editors to that of structured editors by measuring and comparing the number of keystrokes (atomic user input actions) required to achieve the same task.
For example, let’s consider creating an empty statement block for a method in Microsoft Visual C# 2005:
void Foo()
{
}
It takes three to four keystrokes to insert two blank lines and to position the cursor on the first line (either [Ctrl+Enter] twice or [Enter], [Enter], [UpArrow], [UpArrow]). Then it takes three keystrokes to type in “void “ (IntelliSenseTM completes “vo” to “void“ when [Space] is pressed) and another five for “Foo()”. And then it takes 6 keystrokes to insert the curly braces and to position the caret in between with the right indentation. One could accomplish the same with just 8 keystrokes instead of 18, which might seem not a big difference at first, but it definitely gives an overall improvement of editing experience.
It should be impossible for the caret to enter the indentation space to the left of the blocks. If the code is properly formatted (and this always should be the case), there is no need to edit anything to the left of the first significant character in the line. Now it is possible to penetrate the indentation space by pressing the [Left] or [Home] key. All the tabulation should be done automatically, and hence the need to penetrate the left tabulation margin should be eliminated.
However, experienced programmers are used to typing so fast, that this doesn’t bother them at all. Besides, some languages (for example VB.NET 2005) take more care of typing, completion and formatting (code snippets, auto-format on paste, etc), which reduces typing efforts to a minimum. So it is a common belief that the usability of traditional text editors is not an issue, especially in presence of such enhancement tools as, for instance, JetBrains ReSharper ([ReSharper]) or Whole Tomato Visual Assist X ([VAssist]). However for beginners, a learning curve to use an editor effectively is still pretty steep, so formatting and the necessity to take care of the syntax is an issue.
The black-box nature of the editor and the compiler dictates some implementation peculiarities when developing an IDE. One of the biggest ones is the complexity of the round-tripping between text and AST. The one direction is more or less straightforward – pretty-printing, auto-formatting and code generation. The other one is the tricky one – going from code to the AST. This complexity is classically being tackled by the parser – in the sense of the famous dragon book ([AhoSeUl]). However what the successes of the compiler science don’t currently fully cover is the implementation of the language service: “understanding” code and providing intelligent feedback about it. The typical problem is implementing the expression finder and the resolver – given a text stream and the caret position, it is required to reconstruct the language construct under cursor and to provide user feedback about it (code completion, method info, parameter info or even colorizing). This task requires finding the current context (find the class and method that currently contain the caret, as well as the current expression), reparsing the necessary text, updating the internal representation and actually performing the task.
The implementation complexity of round-tripping is due to the fact that most IDEs currently are built around the text data structures, and not around the AST.
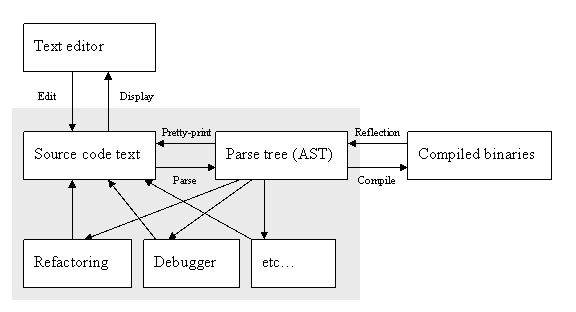
Figure 4 – round-tripping between the AST and IDE components through code
To avoid this complexity, an IDE could be built around precisely defined, language-aware and observable syntax trees, which would serve as the Model in the MVC triple mentioned in [GoF]. A text editor should be just a View, a thin presentation layer which maps user edits to the AST using a controller (a set of hierarchical controls representing language constructs). All other IDE components should only deal with the AST (also often called DOM, CodeDOM, Code Model, Intermediate Representation, Parse Trees, etc.).
Like a database management system guarantees the fulfilment of ACID principles, the IDE should guarantee the integrity of its data structures. The reasons why people invented DBMS to replace plain text are often the same for the source code (see [SCID]).
A compiler shouldn’t be a black-box, but a clean API surface instead, which exposes methods to transparently operate on the AST and to transform it, thus making the compile functionality reusable and extensible (pluggable). In such a way one could easily plug-in custom transformations or code generations between the parser and the code generator. Authors of IDE extensions could thus reuse the compiler functionality, without the need for own third-party parser, resolver, etc.
A debugger could map to language constructs instead of text positions in code, thus preventing that text positions can get out of sync. Thus many known bugs with line and column number offsets could be easily prevented.
This idea brings us to the possible approach of using structured editors to directly operate on the AST:
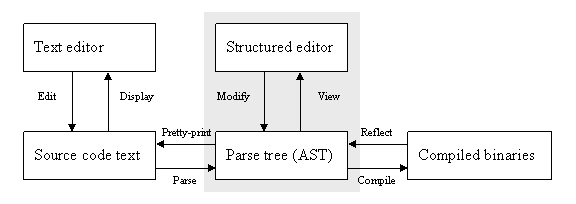
Figure 5 – a structured editor directly operates on the AST
Shifting attention to the AST instead of text data structure would allow bypassing the round-tripping step:
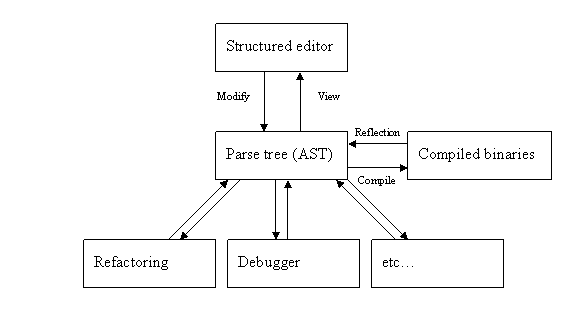
Figure 6 - a possible architecture of an IDE built around the AST
It is important to understand that an architecture of an IDE built around a structured editor and syntax trees doesn’t necessarily imply that the source code has to be stored in a different format, perhaps in a database. The source code could still be stored in usual files. The file format of programs doesn’t even need to change. A parser could load the AST from source, and a pretty-printer could save the AST back into the source code files. The editor could even preserve user’s formatting when saving.
Previous: 1.2. Integration of an editor with the IDE